What is Style Transfer?
Over the last decade, Deep Neural Networks (DNNs) have rapidly emerged as the state-of-the-art for several AI (Artificial Intelligence) tasks e.g., image classification, speech recognition, and even playing games. As researchers tried to demystify the success of these DNNs in the image classification domain by developing visualization tools (e.g. Deep Dream, Filters) which help us understand “what” exactly is a DNN model “learning”, an interesting application emerged which made it possible to extract the “style” of one image and apply it to another image with different “content”. This was termed as “Image Style Transfer”.
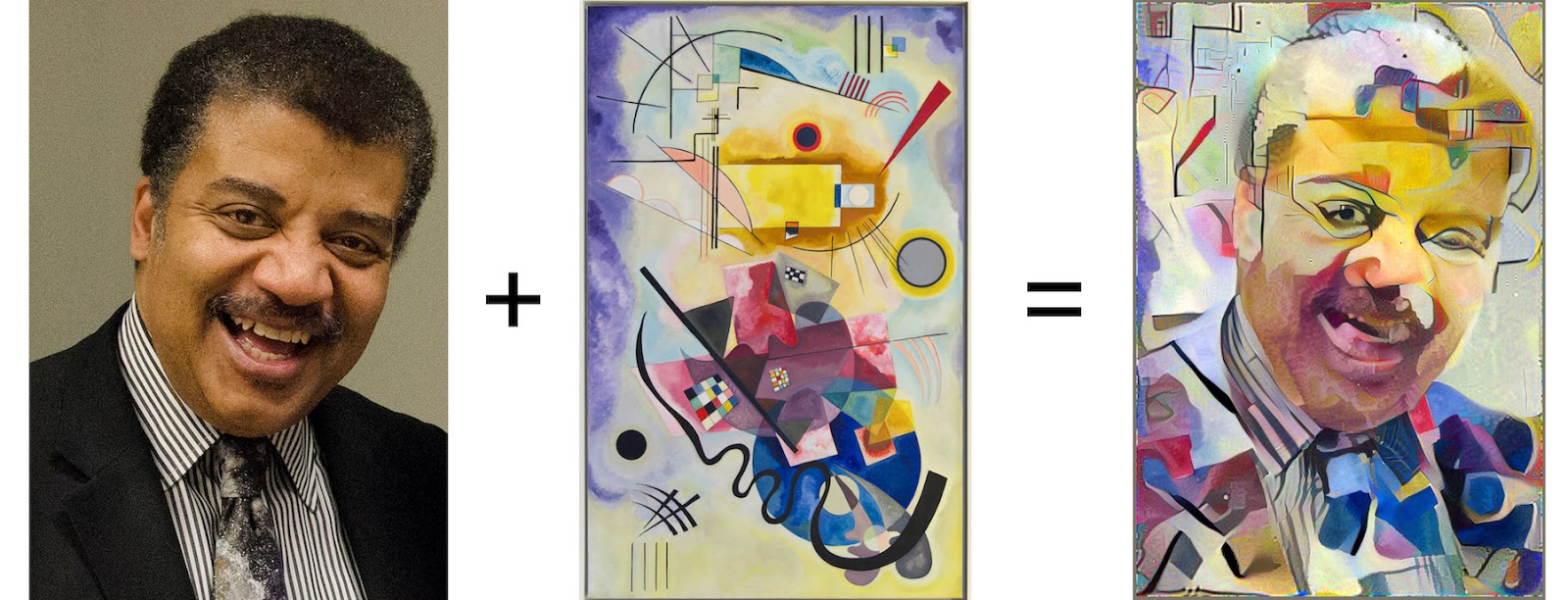
This not only sparked interest among numerous other researchers (e.g., 1 and 2), but also spawned several successful mobile applications like Prisma. Over the last couple of years. these image style transfer methods have undergone significant improvements leading to some impressive results.


For a short intro to how these algorithms work, check out the video below.
However, in spite of the success with images, the application of these techniques to other domains such as audio or music has been rather limited (see 3 and 4) and the results are far less convincing than those achieved using images. This suggests that this is a harder problem. In this study, we want to explore musical style transfer in more detail and arrive at some possible approaches to tackle this problem.
Why is Style Transfer for Music Hard?
Before digging into why style transfer for music is hard, we need to first ask what is Style Transfer in music? The answer to this is not trivial. For images, the concepts of content and style are intuitive. While image content is described by the objects present in the image, e.g., dogs, houses, faces, etc., image style is understood as colors, lighting, brush-strokes and texture of the image.
However, music is semantically abstract and multi-dimensional in nature. Musical content can mean different things in different contexts. Often, one would associate musical content with the melody and musical style with the orchestration or harmonization. However, content could also refer to lyrical content and the different melodies used to sing those lyrics could be interpreted as different styles. In a classical music setting, musical content could be defined as the written score (which includes harmonization as well), whereas style can be the interpretation of the score by the performer wherein the performer adds his/her own musical expression (by deviating from and adding to the score). To get a better idea of what Style Transfer in music could be, check out these two interesting videos below.
The latter actually uses several machine learning techniques to achieve the results.
Thus, style transfer for music is, by definition, not easily defined. There are other key factors which make this even more challenging:
- Music is NOT well-understood by machines (yet !!): The success of style transfer for images actually stems from the success of DNNs at image understanding tasks such as object detection. Since DNNs are able to learn features which can discriminate between different objects in images, back-propagation techniques can be leveraged to morph a target image to match the features of the content image. While we have made significant progress in the development of DNN based models for music understanding tasks (e.g., melody transcription, genre detection, etc.), we are still far from the results achieved in the image domain. This is a serious limitation for style transfer in music. The models we have now simply don’t learn “excellent” features capable of categorizing music and hence, direct application of the style transfer algorithms used in the image domain do not give similar results.
- Music is Temporal: Music is a time-series data i.e. a piece of music evolves over time. This makes learning difficult. Even though Recurrent Neural Networks (RNNs) and LSTMs (Long Short-Term Memory) have enabled learning temporal data more efficiently, we have yet to develop robust models able to learn to reproduce the long-term structure which is observed in music (side-note: this is an active area of research and researchers at the Google’s Magenta team have had moderate success at this).
- Music is Discrete (at a symbolic level at least !!): Symbolic music or written music is discrete in nature. In the Equal Temperament system which is the most popular tuning system used currently, musical pitches are constrained to occupy discrete positions on the continuous frequency scale. Similarly, note durations also lie in a discrete space (usually quantized to quarter-notes, whole-notes, etc.). This makes it rather hard to adapt pixel-wise back-propagation methods (used for images) to the symbolic music domain.
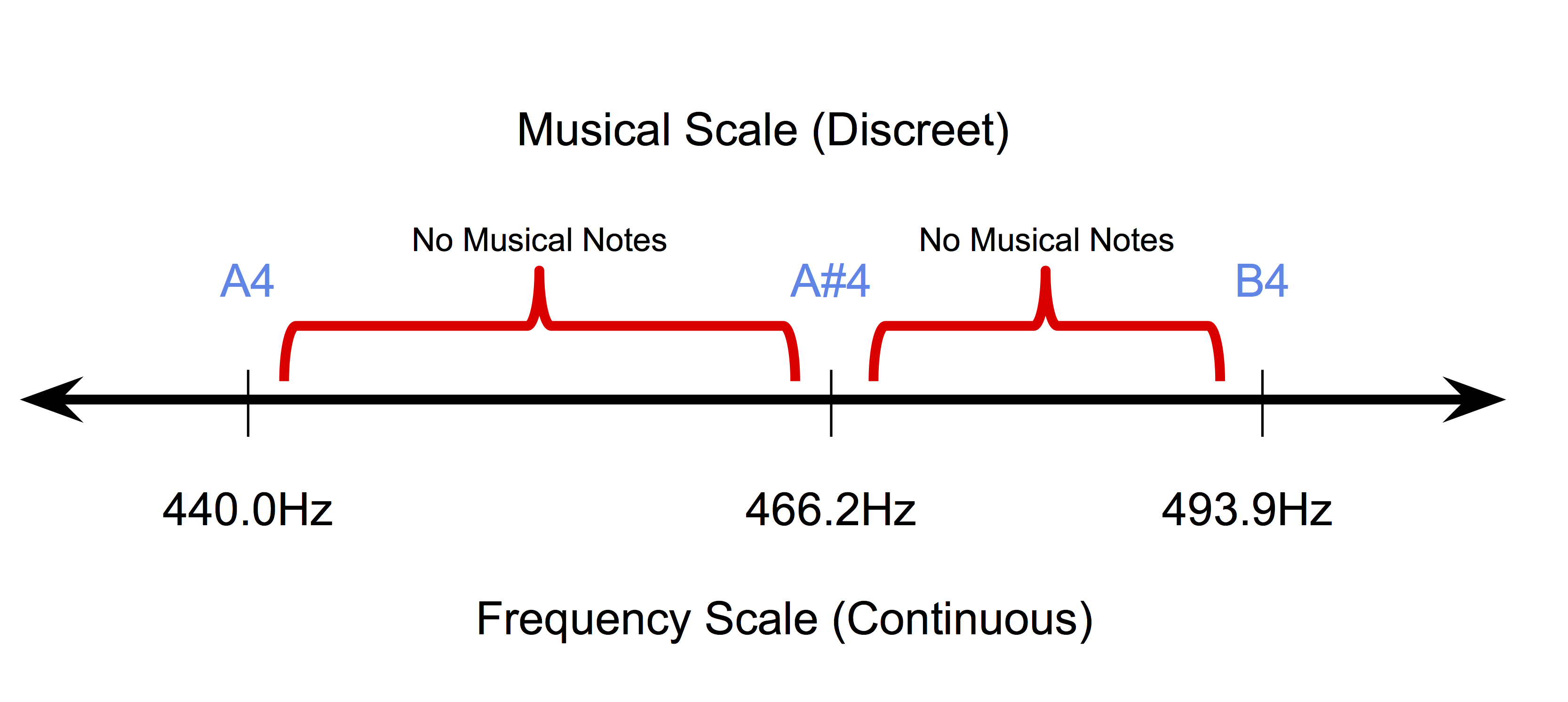
Hence, techniques used in image style transfer don’t logically extend to music directly. For style transfer algorithms to work for music, they need to be re-designed with a strong emphasis on musical concepts and ideas.
Why do we need Style Transfer for Music?
Before delving into how we can tackle this problem, it is also important to understand why is this a problem worth solving. As with images, potential applications for musical style transfer are quite interesting. A direct application of such a technique would be to develop tools to help composers. For e.g. an automatic tool which can transform a melody using orchestrations from different genres would be extremely useful for a composer allowing him/her to try different ideas quickly. Such tools might also find traction amongst DJs looking to mash-up songs with different styles.
An indirect though rather significant outcome of improvements in musical style transfer would be improvements in music informatics systems. As explained in the previous section, for style transfer to work for music data, the models that we develop need to be able to “understand” different aspects of music better.
Simplifying the Style Transfer problem for Music
Looking at the nature and complexity of the task at hand, we start with a very simple case of analyzing monophonic melodies for different genres of music. Monophonic melodies are sequences of notes where each note is described by its Pitch and Duration. While the Pitch progression mostly adheres to the scale of the melody, the Duration progression is dependent on the Rhythm. As a starting point, we can thus make a clear distinction between Pitch Content and Rhythmic Style as two entities using which we can rephrase the Style Transfer problem. By working with monophonic melodies for now, we also avoid having to deal with problems such as orchestration and lyrics.
In the absence of pre-trained models capable of successfully learning features to distinguish between pitch progressions and rhythms of monophonic melodies, we first introduce an extremely simple approach to style transfer for music. Instead of trying to morph pitch content learned from a target melody with the rhythmic style learned from a target rhythm, we try to learn pitch and duration patterns of different genres separately and then attempt to fuse them together later. An overview of the approach is shown below.
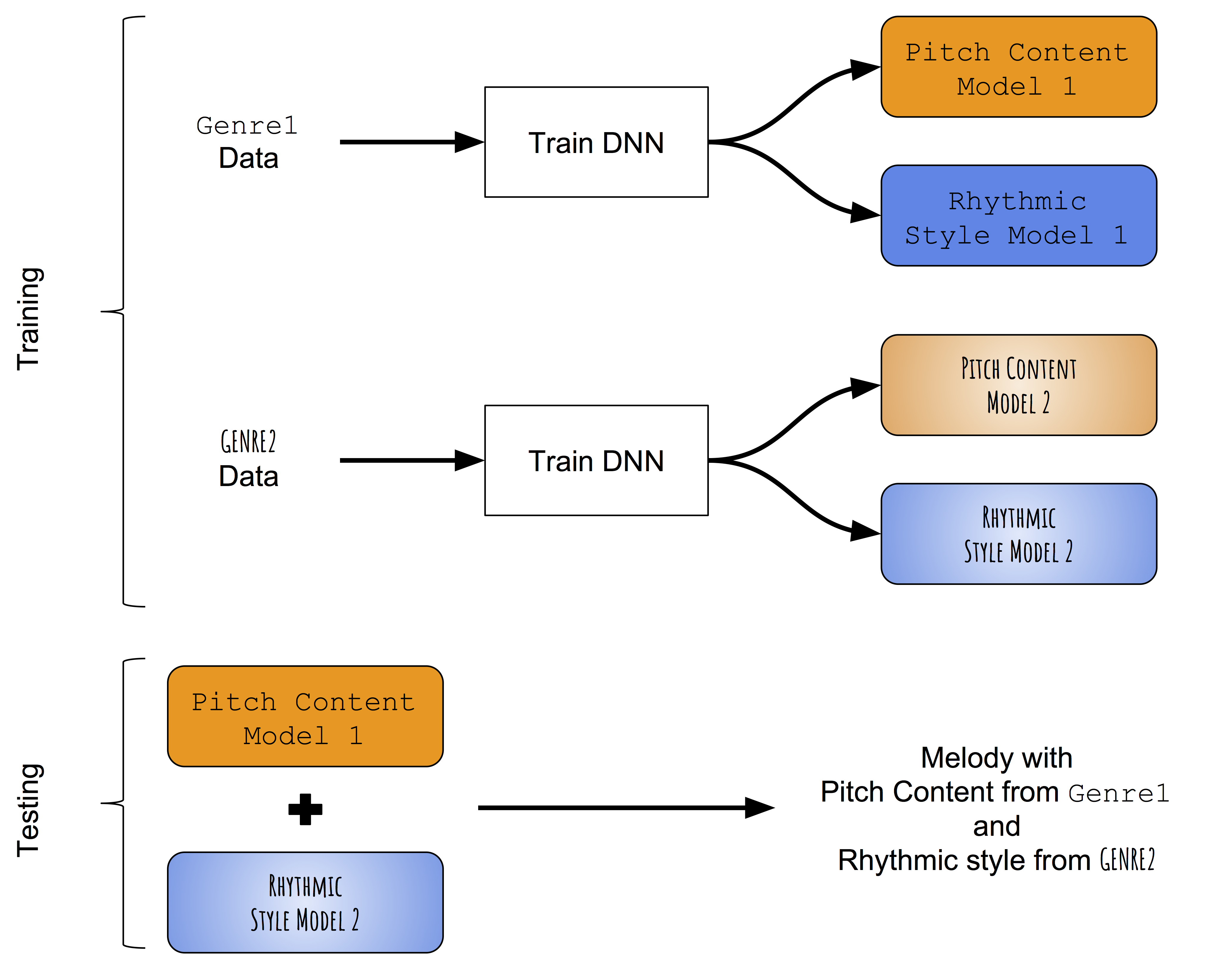
Learning pitch and rhythm progressions separately
Data Representation:
We represent monophonic melodies as sequence of musical notes wherein each musical note has a pitch and a duration index. To make the representation key independent we use an interval based representation, where the pitch of the next note is represented as a deviation (+/- \(x\) semitones) from the pitch of the previous note. For both pitch and duration, we create 2 dictionaries in which each discrete state (+1, -1, +2, -2 etc. for pitch and quarter-note, whole-note, dotted-quarter note, etc., for durations) is assigned a dictionary index.
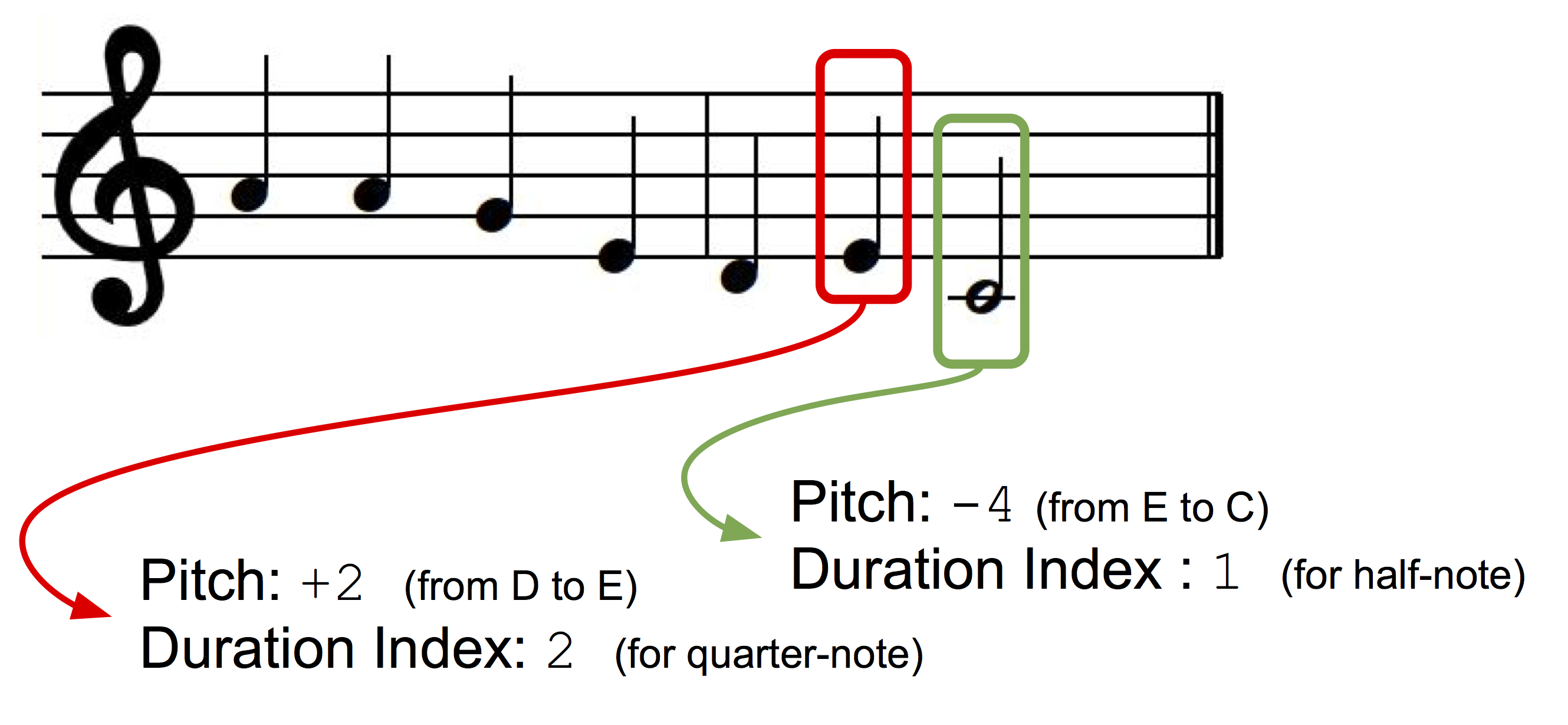
Model Architecture:
For this task, we use a model architecture similar to one used by Colombo et al. 5, in which they simultaneously train 2 LSTM based networks for one genre of music: a) a Pitch network that learns how to predict the next Pitch given the previous note and previous duration, b) a duration network that learns how to predict the next duration given the next note and previous duration. Additionally, we add embedding layers before the LSTM networks for mapping the input pitch and duration indices into learnable embedding spaces. The network architecture is shown in the Figure below.
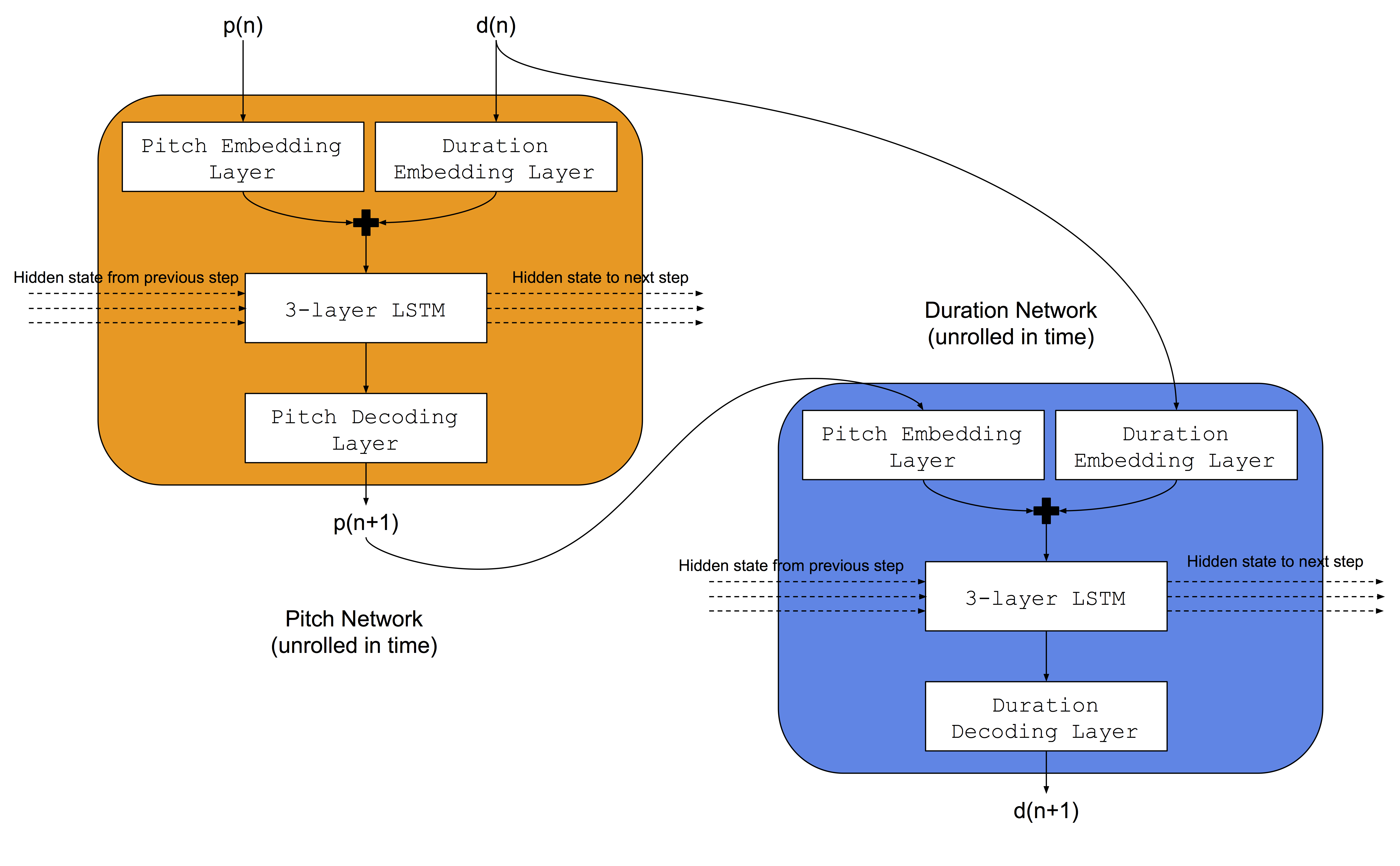
Training Procedure:
For each genre of music, both the pitch and duration networks are trained simultaneously. We use two datasets: a) Norbeck Folk Dataset comprising of around 2000 Irish and Swedish folk melodies, b) A Jazz dataset (not available publicly) comprising of around 500 Jazz melodies.
Fusion of Trained Models:
During test time, a melody is first generated using the pitch and duration networks trained on the first genre (say Folk). Then, the pitch sequence of the generated melody is used as an input to the duration network trained on the different genre (say Jazz) resulting in a new duration sequence. Thus, the melody created by combining these has a pitch sequence conforming to first genre (Folk) and a duration sequence conforming to the second genre (Jazz).
Preliminary Results
Short excerpts of a couple of sample outputs are shown below:
| Folk Pitch with Folk Duration: |

| Folk Pitch with Jazz Duration: |

| Jazz Pitch with Jazz Duration: |

| Jazz Pitch with Folk Duration: |

Conclusion
Even though the current algorithm is a good place to start, it has a few critical shortcomings:
- There is no way to “transfer style” based on a specific target melody. The models learn pitch and duration patterns from a genre and hence all transformations are generalized to a genre. It would be ideal to be able to morph a given piece of music to the style of a specific target song/piece.
- There is no way to control the degree to which the style is to be modified. It might be very interesting to have a “knob” which can control this aspect.
- There is no way to preserve musical structure in the transformed melody when genres are fused. Long-term structure is essential to music appreciation in general and for the generated melodies to be musically aesthetic, musical structure needs to be maintained.
We will explore ways to overcome these shortcomings in subsequent works.